





除了集合之外,Kotlin 标准库还包含另一种类型 - 序列 (Sequence<T>)。 与集合不同,序列不包含元素,它们在迭代时生成元素。
序列提供与 Iterable 相同的功能,但实现了另一种多步骤收集处理方法。
当 Iterable 的处理包括多个步骤时,它们会急切地执行:每个处理步骤完成并返回其结果 - 一个中间集合。 在此集合上执行后面的步骤。
反过来,序列的多步处理会在可能的情况下延迟执行:仅当请求整个处理链的结果时才会发生实际计算。
操作执行的顺序也不同:Sequence 对每个元素逐一执行所有处理步骤。 反过来,Iterable 完成整个集合的每一步,然后继续下一步。
因此,序列可以让你避免构建中间步骤的结果,从而提高整个集合处理链的性能。 然而,序列的惰性性质增加了一些开销,这在处理较小的集合或进行更简单的计算时可能会很重要。
因此,应该同时考虑 Sequence 和 Iterable,并决定哪一种更适合你的情况。
构造
From elements
1 | val numbersSequence = sequenceOf("four", "three", "two", "one") |
From an Iterable
1 | val numbers = listOf("one", "two", "three", "four") |
From a function
创建序列的另一种方法是使用计算其元素的函数来构建它。 要基于函数构建序列,请将此函数作为参数调用 generateSequence()。
或者,可以将第一个元素指定为显式值或函数调用的结果。 当提供的函数返回 null 时,序列生成停止。 因此,下面示例中的序列是无限的。
1 | val oddNumbers = generateSequence(1) { it + 2 } // `it` is the previous element |
要使用 generateSequence() 创建有限序列,请提供一个在所需的最后一个元素后返回 null 的函数。
1 | val oddNumbersLessThan10 = generateSequence(1) { if (it < 8) it + 2 else null } |
From chunks
最后,有一个函数可以让你逐个或按任意大小的块生成序列元素 —— sequence() 函数。 该函数采用包含 yield() 和 yieldAll() 函数调用的 lambda 表达式。
它们将一个元素返回给序列使用者,并挂起 sequence() 的执行,直到使用者请求下一个元素。yield() 将单个元素作为参数; yieldAll() 可以采用 Iterable 对象、Iterator 或另一个 Sequence。yieldAll() 的 Sequence 参数可以是无限的。 然而,这样的调用必须是最后一个:所有后续调用将永远不会被执行。
1 | val oddNumbers = sequence { |
Sequence operation
根据其状态要求,序列操作可以分为以下几组:
- Stateless 操作不需要状态并独立处理每个元素,例如
map()或filter()。 Stateless 操作还可能需要少量恒定的状态来处理元素,例如take()或drop()。 - Stateful 操作需要大量的状态,通常与序列中元素的数量成正比。
如果一个序列操作返回另一个延迟生成的序列,则称为 intermediate 序列。 否则,操作是 terminal。 terminal 操作的示例有 toList() 或 sum()。 序列元素只能通过 terminal 操作来检索。
序列可以迭代多次; 然而,某些序列实现可能会限制自己只能迭代一次。 他们的文档中特别提到了这一点。
Sequence processing example
通过一个例子来看看 Iterable 和 Sequence 的区别。
Iterable
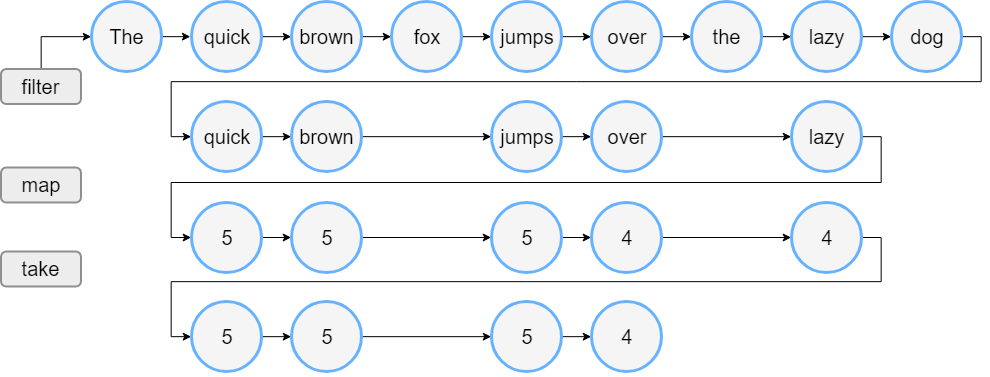
假设有一个单词列表。 下面的代码过滤长度超过三个字符的单词并打印前四个这样的单词的长度。
1 | val words = "The quick brown fox jumps over the lazy dog".split(" ") |
当运行此代码时,将看到 filter() 和 map() 函数的执行顺序与它们在代码中出现的顺序相同。 首先,会看到所有元素的 filter: ,然后是过滤后留下的元素的 length: ,然后是最后两行的输出。
这是列表处理的方式:
Sequence
1 | val words = "The quick brown fox jumps over the lazy dog".split(" ") |
此代码的输出显示仅在构建结果列表时才调用 filter() 和 map() 函数。 因此,首先会看到文本行 “Lengths of..”,然后序列处理开始。
请注意,对于过滤后留下的元素,map 会在过滤下一个元素之前执行。 当结果大小达到 4 时,处理停止,因为这是 take(4) 可以返回的最大可能大小。
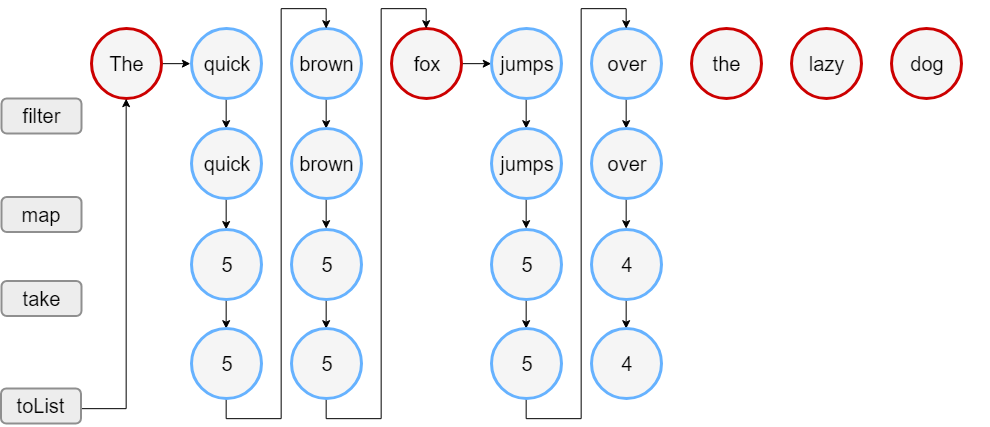
在此示例中,序列处理需要 18 个步骤,而不是对列表执行相同操作的 23 个步骤。